개요
On-Premise 환경에서 Kubernetes 노드 간의 데이터 공유는 NFS를 활용하여 static pv-pvc방식으로 마운트를 통해 수행하고 있었는데 갑자기 어느 순간부터 특정 노드에 Pod가 배포되면 Init 상태에서 넘어가지 못하는 이슈를 확인했습니다.
클러스터엔 워커 노드가 총 3개였으며 2개의 노드는 계속 잘 배포되고 있어 해당 pod를 디버깅했으나 별다른 로그나 정보가 나와있지 않아 일시적인 이슈인가 싶어 rollout 명령어를 통해 재시작을 해도 해당 노드에선 계속 Pod가 배치될 때마다 Init 상태로 넘어가지 않는 상태가 지속됐습니다.
PV-PVC 마운트 상태는 ArgoCD에서 확인한 결과 이상이 없었으나 파드가 구동되는 순간 kubelet이 PVC정보를 통해 마운트를 시도할 때마다 붙지 않는 것 같아 커널과 system 로그를 확인한 결과 이슈를 확인할 수 있었습니다.
Kubernetes 상에서 describe등에서 event로그로도 나오지 않고 PV-PVC의 bound과 마운트 상태가 정상적이어도 발생할 수 있는 NFS기반의 환경에서의 문제를 확인하고 어떻게 해결했는지도 말씀드리도록 하겠습니다.
환경
Kubernetes
- v1.33 Kubernetes
OS
- Ubuntu 22.04
NFS
- NFS v4.1
CRI
- CRI-O
PV&PVC
- Static Mount기반 NFS v4.1 프로토콜을 활용
위 환경을 기반으로 배포하고 있던 Kubernetes 환경에서의 서비스였으며 이 환경을 기반으로 문제를 확인 & 분석해 보겠습니다.
문제 현상
개발 클러스터 중 하나의 클러스터에서 POD의 배치가 Init 상태에서 넘어가지 않았고 파드의 스펙, 종류를 가리지 않고 Scheduler가 해당 노드에 배치하기로 결정하면 배치되는 모든 파드가 Init상태에 머무른 문제는 다음과 같이 확인이 가능합니다.

Init 상태에서 50분 동안 지속되며 상태값이 바뀌거나 장애가 확인되지 않아 k describe 명령어로 디버깅을 진행했으나 하단과 같이 scheduler가 노드에 스케줄링했던 로그만 나오고 Init에서 멈춰있던 상태의 원인은 확인할 수 없었습니다.
이 상황에서 문제가 정확하게 확인되지 않아 이슈를 찾기가 어려워 kubelet이 파드를 생성하는 과정에서 문제가 있었는지 확인했고 계속하여 파드에 pvc 마운트를 수행하지 못해 restart 해야 한다는 정보였지만 이 역시 restart로는 해결되지 않았습니다.

문제의 원인을 정확히 알기 위해 커널 로그를 확인했고 NfSv4 blocked 정보에서 NFS Blocked로 PVC 마운트에 실패한 이유가 파드가 데이터를 공유하는 NFS로 Client가 Server와 통신하는 과정에 문제가 생긴 것을 알 수 있었습니다.
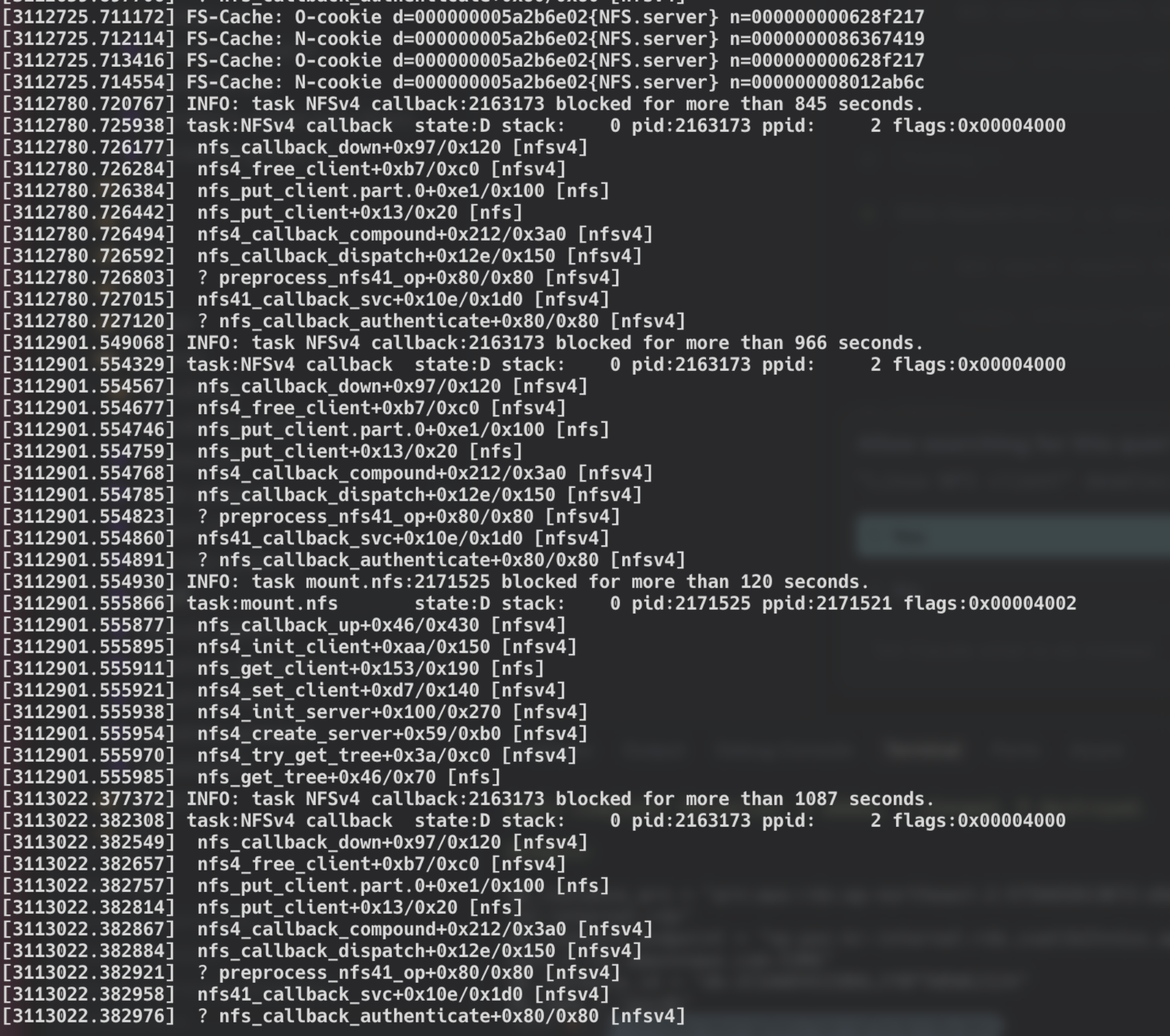
커널 로그를 확인한 결과 NFS Client 프로세스가 D state에서 멈춰 계속해서 재시도해도 Blocked, timeout 이후 영구적으로 대기하고 있는 것을 알 수 있었습니다.
그리하여 파드가 생성되지 않고 로그가 소프트웨어에서 바로 확인되지 않았던 것의 진짜 원인은 NFS Client가 Server와 통신하는 과정에서 D State로 머물고 이후 모든 NFS를 통해 연결하는 파드의 장애가 발생한 것으로 확인할 수 있었습니다.
여기서 잠깐 D State가 의미하는 것이 무엇인지 알아보겠습니다.
리눅스에서 ps/top의 프로세스 상태(STAT)가 D로 표시되면, 해당 태스크가 uninterruptible sleep(인터럽트 불가 수면) 상태로 I/O 완료를 기다리는 중임을 의미합니다.
- 즉, 사용자 공간에서 시그널로 쉽게 깨울 수 없는 커널 대기 상태이며, I/O가 끝나거나 커널이 명시적으로 깨워줄 때에만 다음 상태로 진행합니다.
- ww “I/O 등으로 인해 커널 내부에서 깨우기 어려운 대기”가 발생했음을 나타내는 관측값으로 이해하는 것이 정확합니다.
- 프로세스의 재부팅 등이 아니라 아예 노드를 재부팅하지 않는 한 해결되지 어려운 상태라고 이해하는 것이 적절합니다.
또한 커널 로그에 task <name>:<pid> blocked for more than <N> seconds가 반복된다면, 이는 커널의 **hung task 감지(CONFIG_DETECT_HUNG_TASK)**가 D 상태 태스크가 일정 시간 이상 스케줄되지 못한 상황을 경고로 출력한 것입니다
- 이 경우 “일시적 대기”를 넘어, 대기 원인이 해소되지 않아 장시간 정체되는 상태로 간주하고 문제의 원인이 무엇인지 확인하고 이 원인을 해결하여 다시금 프로세스가 D State로 빠지지 않게 재발방지 시스템을 구축하는 것이 중요합니다.
문제 분석 - 왜 NFS Client가 D State에 빠지고 연결이 제대로 되지 못했던 것 인가?
핵심 메커니즘
1) NFSv4는 서버가 클라이언트 상태를 기억하는(stateful) 프로토콜입니다
- NFSv4는 서버가 클라이언트를 clientidclientid로 식별하고, 파일에 대한 open/lock 같은 상태를 서버 쪽에 유지합니다.
- 클라이언트의 상태를 유효하다고 인정하는 유효시간의 개념이며 lock, delegation, open과 같은 모든 state는 lease에 종속되며, 클라이언트는 주기적 renew를 통해 해당 state들의 유효성을 유지해야만 합니다.
- 네트워크의 장애 등 이슈로 인해 클라이언트가 갱신하지 못한다면 해당 clientid의 모든 상태를 폐기(reclaim 불가)하고, 이후 I/O는 재오픈·재락이 필요합니다
2) Linux 커널 NFS 클라이언트는 공유 클라이언트 레코드를 전제로 합니다.
- 커널 소스에서 NFS 클라이언트 구조체를 shared client record로 명시합니다.
- 커널에서 확인하면 struct nfs_client라는 Client 구현체는 노드에서 NFS 서버 하나당 1개이기 때문에 동일 NFS 서버로 갈 때 Linux에서는 동일 서버로 향하는 모든 마운트가 하나의 nfs_client(clientid)를 공유하고 그 client가 대표로 lease를 갱신하게 됩니다.
상태 복구 경로에서의 블로킹과 D-state 전파
NFSv4에서 lease 만료 이후 발생한 I/O는 Linux 커널에서 **“새 client 생성”이 아니라 “기존 client 상태 복구(recovery)” 경로로 처리됩니다.
이 복구 로직은 struct nfs_client 단위로 수행되며, 동일 서버를 사용하는 모든 마운트가 이 경로를 공유합니다.
이 과정에서 커널은 다음과 같은 동작을 수행합니다.
- nfs_client 단위의 recovery mutex 획득
- 상태 복구를 위한 recovery workqueue 대기
- callback 서비스 초기화, 세션 재확인 등 공용 초기화 경로 진입
예를 들어, 커널의 nfs_callback_up()은 callback thread가 기동 되어 있지 않은 경우 이를 초기화하는 함수이며, 전역 nfs_callback_mutex로 보호됩니다.
이러한 초기화 및 복구 단계는 client 단위로 직렬화되기 때문에, 한 마운트에서 발생한 지연이나 블로킹은 동일 NFS 서버를 사용하는 다른 마운트들까지 함께 대기 상태로 묶을 수 있습니다.
이때 해당 경로로 진입한 태스크는 커널 내부에서 uninterruptible sleep(D-state) 상태로 전환되며, 시그널이나 user space 영역에서의 재시도로는 복구가 불가능한 상태가 됩니다.
NFS v4에서 문제를 일으켰던 NFS Client의 공유 구조
- 한 마운트의 I/O 블로킹 = 동일 nfs_client를 쓰는 모든 마운트에 전파
- 그래서:
- 하나의 Pod
- 하나의 볼륨
- 하나의 프로세스
에서 시작된 문제가 노드 전체 NFS 워크로드로 확산
이게 *shared client 구조가 장애를 증폭시키는 지점”입니다.
Linux NFS 클라이언트는 서버 단위로 client 상태를 공유하며, lease 만료 이후 발생한 I/O를 ‘새 client 생성’이 아닌 ‘기존 client 상태 복구’로 처리합니다.
이 복구 경로에서 커널 스레드가 uninterruptible sleep에 진입하면, 동일 client를 공유하는 모든 마운트가 함께 블로킹된다라고 모든 문제를 정리할 수 있겠습니다.
결론
이로 인해 처음엔 “단일 볼륨 문제”가 아니라 노드 단위 NFS 정지”처럼 관측되었으며, 사용자 영역에선 디버깅이나 관측도 어려운 것은 커널 영역에서 문제가 발생하여 모든 마운트를 시도했던 큐가 D State로 빠졌기 때문에 재시도 외에는 해결할 수 없었습니다.
문제 해결
문제 해결(즉각 복구, break-glass)
- 노드 reboot
- D-state에 빠진 커널 태스크 강제 제거
- struct nfs_client / clientid / recovery 상태 전부 초기화
- 유일하게 100% 확실한 즉시 복구 수단
문제 회피(구조적 재발 방지)
- NFSv3 사용
- stateless 프로토콜
- clientid / lease / delegation / recovery 경로 자체가 없음
- 동일 상황에서도 D-state 전파 가능성 대폭 감소
따라서 v3는 해결책이 아니라, 이런 유형의 장애를 구조적으로 피하는 선택지입니다.
이 두 가지 해결책만 존재하는 이유를 설명드리겠습니다.
❌ Pod 재기동 / 프로세스 kill
- D-state = uninterruptible sleep
- 시그널 무시
- mount namespace가 살아 있으면 client 상태 유지
- → 효과 없음
❌ umount / remount
- D-state 태스크가 참조 중이면 umount 불가
- lazy umount도 커널 경로에 따라 실패 가능
❌ “새 clientid로 재연결”
- 이론적으로 가능
- 현실에서는 recovery mutex + workqueue에 묶여 진입 자체가 불가
- shared nfs_client 구조 때문에 개별 마운트 단위 탈출 불가
제가 실제로 시도한 방법은 reboot이며 아직은 V3로의 프로토콜로 전환을 하여 문제를 회피하고 있지는 않고 있습니다.
1년 동안 1번 정도 발생하긴 했으며 제가 그동안 Nfs를 사용했을 땐 보지 못했던 이슈였으나 파드가 hpa와 같은 방식으로 zero to all로 구동되는 방식에서 NFS Client가 내부 네트워크 이슈 등으로 lease를 갱신하지 못한 문제를 처음 겪은 것이었기에 문제를 회피하기에 앞서 문제를 일으킨 부분에 대해 파악했습니다.
NFS V3가 바로 문제를 해결해 주는 방책이긴 하지만 20년도 더 된 프로토콜이며 각 버전 간 취약점, 개발과정의 이유가 있을 거라 생각하여 조금 더 파악하고 배우기 전까지 섣불리 적용하기가 어려웠기 때문입니다.
이 부분에 대해 NFS 프로토콜에 대해 조금 더 파악하는 게시글을 통해 알아보려고 하며 이후엔 어떻게 해결할지 방향을 잡아볼 것 같습니다.
부록
NFS v3를 적용한다면 다시는 이런 문제를 경험하지는 않는다고는 하나 20년 정도 전의 개발된 프로토콜을 쓰는 게 맞는 것 인가? stateful 한 것은 결국 성능을 위해 개발되어 나온 것이 아닌가? 하는 생각도 들어 섣불리 v3로 전환하지는 못했습니다.
애플리케이션의 로그, ArgoCD에선 이것이 문제라는 로그를 확인할 수 없었으며 파드가 배포되어 있는 노드로 접속하여 kubelet을 확인해도 mount시도 시 장애 정도만 나와 PV, PVC의 문제인가?라고 되묻게 했으며 결국엔 커널 로그까지 확인해야 정확히 문제를 확인할 수 있을 만큼 문제가 무엇인지 식별하는 것부터가 어려운 장애라고 생각합니다.
지금까지 kubernetes를 사용하고 nfs를 사용하며 처음 겪었는데 이 문제가 생기기 이전, 이후로 동일한 환경을 조성하여 똑같은 문제를 만드려고 해도 잘 나오지 않을 만큼 재현하기도 쉽지 않은 이슈이기는 합니다...(근데 왜 생겼는지..)
이런 이슈를 경험하여 든 생각은 애플리케이션의 로그만 수집하는 것이 아니라 노드들의 kubelet, 커널의 로그까지 수집하여 오류의 상황을 먼저 인지해야 한다는 것이 첫 번째이며 장애가 발생했을 땐 문제의 해결이 분석보다 우선하여 운영상황을 안정시켜야 하기 때문에 해당 파드를 다른 노드로 전환하여 장애가 발생하지 않도록 시스템화하고 해당 노드는 drain 하여 안정화가 될 때까지 파드를 배치하지 않게 구조화하는 것이 중요하겠구나라고 배우게 됐습니다.
정리/회고
NFS로 공유 볼륨을 사용하는 환경에서 처음 겪은 이슈였으나 이 이슈는 개별 POD나 볼륨, User Space 영역에서 복구할 수 있는 문제가 아니었으며 커널 레벨에서 노드 단위로 문제가 확산되어 문제가 발생했을 땐 Reboot 없이는 해결할 수 없었습니다.
즉각적인 복구 방법이었으며 구조적인 재발 방지를 위해선 현실적으로 NFS v3로 옮겨야 하는 것인가?라는 물음표에 아직도 결론을 내리고 있지는 못하고 있습니다.
다만 NFS v4를 사용하며 커널 레벨과 프로토콜 stateful 한 방식에서 어떻게 노드가 서버와 연결하는지 동작원리에 대해 더 많은 공부를 할 수 있었으며 공유 구조에서의 구조적인 문제점과 동작원리를 파고들며 조금 더 배울 수 있었던 것 같습니다.
사내에선 내부 네트워크의 불안정성이 최근에 커지고 있고 그로 인한 네트워크 이슈가 자주 발생하고 있어 문제가 발생했던 상황에선 Client가 서버의 lease를 갱신해야 하는 시점에서 갱신을 하려다 네트워크 장애가 발생해 문제가 발생한 것으로 생각하고 있습니다.
지금까지 Kuberentes에서 다수의 노드 간 파드의 데이터를 공유하는 방식 중 하나인 NFS를 사용하여 발생하는 문제에 대해 파고들었으며 이 문제는 경험하게 된다면 모니터링, 로깅하려는 지점도 감이 오지 않고 또 하기도 어려우며 레퍼런스를 찾기 어려워 파악하거나 문제를 해결하기가 어려울 거라고 생각합니다.
단순하게는 Reboot를 시도하면 문제가 해결되지만 그건 결과일 뿐이며 과정에서 왜 문제가 발생하게 됐는지 어떻게 발생하게 되는 것인지 Reboot 외 어떤 해결책이 존재하는지 등등 이 글을 통해 인사이트를 얻어가실 수 있으셨으면 좋겠습니다.
저도 또한 블로그를 정리하며 더 많은 것 들을 정리하고 배울 수 있었던 것 같고 추가적인 속편은 NFS 버전 간의 변화, 프로토콜의 특성등에 대해 정리하여 찾아오도록 하겠습니다.
Reference
https://manpages.debian.org/stretch/procps/ps.1.en.html
https://docs.kernel.org/filesystems/nfs/client-identifier.html
https://datatracker.ietf.org/doc/html/rfc8881
'TroubleShooting > Os-Infra' 카테고리의 다른 글
| Docker,Kubernetes - nvidia-smi: Failed to initialize NVML: Unknown Error — cgroup 관리 주체 (systemd cgroupfs)로 인한 GPU 접근 권한 상실 이슈 (1) | 2026.01.14 |
|---|---|
| Ubuntu 22.04 설치 과정 중 네트워크 드라이버 인식 불가 문제 해결 (5) | 2025.08.11 |
