배경
실무에서 Docker 기반으로 서비스 테스트를 진행하는 과정에서, 주변 동료 개발자로부터 제기된 이슈를 공유받은 적이 있었습니다.
이슈의 핵심은 두 가지였습니다.
첫째, Docker 컨테이너에 설치된 ChromeDriver의 버전과 Spring에서 사용하는 Selenium 라이브러리 버전이 맞지 않는다는 점.
둘째, Selenium을 통해 구동한 브라우저가 테스트 실행 도중 알 수 없는 원인과 함께 반복적으로 종료된다는 점이었습니다.
당시에는 Dockerfile 안에서 라이브러리와 드라이버 버전을 명시적으로 고정하여 문제를 해결할 수 있었습니다.
이후 테스트는 정상적으로 진행되었지만, 추가로 한 가지 흥미로운 현상이 확인되었습니다.
바로 브라우저가 구동되는 시간이 길어질수록, 컨테이너가 점유하는 메모리가 꾸준히 증가하고 있다는 점이었습니다.
이 메모리 증가 현상은 당시 주요 원인 분석 범위에 포함된 것은 아니었지만 논의 중 곁가지처럼 이어진 화제가 있었습니다.
“혹시 컨테이너 안에서 생성된 프로세스가 제대로 회수되지 않고 남아 있는 것은 아닐까?” 하는 질문이 오갔던 것이죠.
결과적으로 Selenium과 ChromeDriver 사례에서의 메모리 이슈와 좀비 프로세스와 직접적인 연관은 없었습니다.
브라우저 프로세스는 단순히 종료되지 않고 살아남아 메모리를 차지한 것이었고, 좀비 프로세스처럼 커널 메타데이터만
남는 상태는 아니었습니다만 좀비 프로세스가 야기할 문제를 고려하여 이 부분도 추후 설명할 설정과 함께 해결했었습니다.
이 과정을 통해 Docker 환경에서 프로세스 관리와 자식 프로세스 회수 문제, 즉 좀비 프로세스 개념을 배울 수 있었습니다.
따라서 이 글에서는 당시 사례를 출발점으로 삼아, 컨테이너 환경에서 메인 프로세스(PID 1)가 자식 프로세스를 어떻게
회수하지 못할 수 있는지, 그리고 그 결과 좀비 프로세스가 발생하는 구조를 다뤄보려 합니다.
이슈가 발생했던 환경
- Docker
- Selenium과 같이 프로세스를 생성하는 라이브러리
- amd64 Platform 기반의 gradle 8.9.0이 설치되어 있는 JDK17 이미지
위와 같은 환경에서 이슈를 확인했었으나 현재 해당 이슈에 대한 자료가 남아있지 않아 비슷한 환경으로
이슈를 재현하고 해결해 나가는 과정을 보여드리겠습니다.
문제 현상
지금부터 Docker 환경에서의 Zombie 프로세스를 재현하고 문제 현상을 분석해 보도록 하겠습니다.
함께 살펴볼 예제는 gpt의 도움을 받아 생성했으며 코드와 상세설명은 덧붙이도록 하겠습니다.
좀비 프로세스를 재현하기 위한 과정을 먼저 설명드리고 길어질 수 있는 코드블록은 토글형태로 게시하겠습니다.
1. dockerfile을 기반으로 일반화한 환경에서 실행하는 명령어에서 자식 프로세스를 생성합니다.
2. 생성된 자식 프로세스는 즉시 종료되고 부모에 의해 반환되지 않는 좀비 프로세스로 변환된다.
3. 각 명령어를 통해 좀비 프로세스가 어떻게 존재하게 되는지 파악한다.
1. Dockefile 작성
FROM ubuntu:22.04
RUN apt-get update && apt-get install -y build-essential procps
COPY pid1_zombie.c /pid1_zombie.c
RUN gcc -O2 -static -s -o /pid1_zombie /pid1_zombie.c || gcc -O2 -o /pid1_zombie /pid1_zombie.c
CMD ["/pid1_zombie"]2. 자식 프로세스를 생성하여 좀비 프로세스로 만들 pid1_zombie.c 코드 작성
#define _GNU_SOURCE
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <signal.h>
#include <stdio.h>
#include <stdlib.h>
int main(void) {
// SIGCHLD 기본 동작(디폴트) 유지: 자식 종료 시 좀비로 남게 함
struct sigaction sa = {0};
sa.sa_handler = SIG_DFL; // 기본 처리기
sa.sa_flags = 0; // SA_NOCLDWAIT 사용 안 함
sigaction(SIGCHLD, &sa, NULL);
printf("PID1=%d: spawning children...\n", getpid());
for (int i = 0; i < 100; i++) {
pid_t pid = fork(); // 1) 부모 프로세스를 복제해 "자식" 하나를 만든다
if (pid == 0) { // 2) fork의 반환값이 0이면 "여기는 자식" 분기
_exit(0); // 3) 자식은 즉시 종료(정상 종료 코드 0) → 좀비 후보
}
// 4) 부모는 어떤 wait()도 호출하지 않음 → 자식의 종료 상태를 회수하지 않음
}
// 좀비가 관찰되도록 충분히 살아있기
sleep(300);
return 0;
}3. Docker Image로 만든 뒤 실행하여 좀비 프로세스의 현황 파악
docker build -t pid1-zombie .
docker run --rm -d --name ztest pid1-zombieztest라는 좀비 프로세스를 양산할 컨테이너를 생성하여 먼저 ps -ef로 현재 프로세스 목록을 확인한 결과 대부분 좀비 프로세스로
존재하고 있었으며 부모 프로세스는 해당 프로세스를 반환(reap)하고 있지 못했습니다.

위 사진에서 보이는 <defunct>라는 상태는 ps()의 매뉴얼을 확인한 결과 좀비 프로세스를 의미하는 것을 알 수 있었습니다.
해당 프로세스가 zombie라고 명확히 알 수 있는 명령어로 좀비프로세스 인지 구체적으로 확인해 보겠습니다.
ps -eo pid=,stat= | awk '$2 ~ /^Z/ {print $1}' | head -n 10 \
| while read -r p; do
echo "PID: $p"
sed -n '1,5p' "/proc/$p/status" | sed 's/^/ /'
echo
done
해당 명령어로 확인한 탑 10개의 프로세스 중 일부 프로세스의 상태값을 출력한 자료입니다.
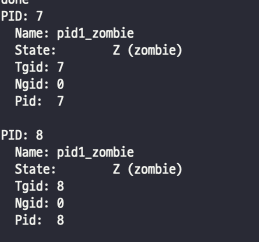
이렇듯 컨테이너 환경에서 PID1번과 관련된 이슈로 확인된 Zombie Process를 재현했으며 sh쉘 환경이나
일반적인 Linux환경에서는 볼 수 없는 이슈라는 것을 알 수 있었습니다.
이 부분은 추후 init process와 linux와의 관계를 엮어 새로운 블로그 글을 작성해 추가하도록 하겠습니다.
현상 분석
Zombie Process란?
문제 현상에서 재현하여 확인한 Zombie Process라는 것을 상태값으로도 알 수 있었는데 그 좀비 프로세스가 정확히 무엇인지
확인해 보도록 하겠습니다.
- 이미 실행을 마쳤지만(자식이 exit로 끝남) 부모가 wait()/waitpid()로 종료 상태를 회수하지 않아,
커널의 프로세스 테이블 엔트리만 남아 있는 프로세스 - ps에서는 <defunct>로 표시되기 때문에 프로세스의 현황을 확인했을 때 defunct process라고도 확인이 가능합니다.
Zombie Process가 생기는 이유는?
- 부모가 fork()/clone()으로 자식 프로세스를 생성합니다.
- 자식프로세스가 exit()/_exit()로 종료합니다.
- 커널은 자식의 사용자 공간 메모리를 해제하지만, 종료 코드·사용량 통계 등 메타데이터를 부모에게
전달하기 전까지 프로세스 테이블에 남겨둡니다. - 부모가 wait()/waitpid()로 이 종료 상태를 회수(reap) 하지 않으면, 자식은 Z(zombie) 상태로 남습니다.
이때 CPU를 쓰지 않고 메모리도 거의 점유하지 않으나, 프로세스 테이블 엔트리는 유지됩니다.
자식 프로세스가 exit() 명령어와 함께 종료되고 나면 메타데이터를 전달하기 전까지 유지되는 프로세스
테이블에서 유지되는 상태에서 wait()등으로 회수(reap)되지 않는 프로세스들이라고 정의될 수 있습니다.
그렇다면 Zombie Process가 야기하는 문제는?
- 프로세스 테이블·PID 슬롯을 점유합니다.
자식이 종료된 뒤 부모가 wait()/waitpid()로 회수하지 않으면, 커널이 그 자식의 엔트리를 유지합니다.
이 엔트리가 곧 PID 슬롯입니다. - PID 한계에 도달하면 새 프로세스 생성이 실패합니다.
시스템 전역 한계(pid_max)나 cgroup 한계(pids.max)에 닿으면 fork/clone/posix_spawn이
EAGAIN(“Resource temporarily unavailable”)으로 실패합니다. 즉, 새 프로세스가 뜨지 않습니다. - 일반 시그널로는 제거할 수 없습니다.
좀비는 이미 종료된 상태이므로 SIGKILL 등으로 사라지지 않습니다.
부모의 wait()/waitpid(), 또는 부모 종료 후 PID 1에 의해 회수될 때만 제거됩니다.
Zombie Process의 개요, 문제 재현, 정의, 문제점등을 알아보았으며 이제부턴 Container 환경에서 왜
이런 문제가 발생하는 것인지 어떻게 해결할 수 있는지를 설명드리겠습니다.
Container환경에서 Zombie Process가 생성되는 이유는?
PID1번이 하는 역할
- 전통적으로 유닉스/리눅스에서 PID 1은 자식(또는 입양된 고아) 프로세스가 종료될 때
wait()/waitpid()`로 상태를 회수(reap) 합니다. 이러한 횟수가 없으면 종료된 자식이 좀비로 남습니다.
컨테이너에선 어떤 프로세스가 PID 1로 위치하는지
- 컨테이너는 자체 PID 네임스페이스를 사용하고, 격리된 container PID 네임스페이스에서 제일 처음 실행된
ENTRYPOINT/CMD 명령이 곧 컨테이너 내부의 PID 1이 되는 구성이 일반적입니다.
이 PID 1이 해당 네임스페이스의 최종 부모로서 자식 종료를 회수해야 합니다.
컨테이너에서 PID1번의 프로세스가 왜 reap를 수행하지 못하는가
- 많은 애플리케이션/스크립트는 PID 1로 실행될 것을 전제하지 않아 SIGCHLD 처리 및 비차단 waitpid() 루프가 없습니다.
그래서 자식(또는 재부모화된 고아) 프로세스가 종료되어도 회수가 누락되면 좀비 프로세스가 누적됩니다.
그럼 Container에서 Zombie Process를 해결하기 위한 방법은?
- sh/bash 같은 쉘 스크립트를 PID1번으로 두고 메인 애플리케이션을 자식 프로세스로 실행
- Docker 내장 init 사용: --init(= Tini) 또는 이미지에 Tini/dumb-init 탑재
- 애플리케이션 자체에 신호·reap 로직을 넣고, Dockerfile은 exec 형식으로
- Ubuntu/Linux에서 PID1로 실행되는 systemd와 같은 프로세스를 활용
해결책은 위와 같이 존재하나 실무에서 적용할 수 있는 해결책은 3가지 중 2번으로 밖에 존재하지 않는다.
1번 방법에서 셸은 기본적으로 자식 프로세스가 종료되면 wait()를 호출해서 상태를
회수(reap)하지만 셸은 종료 신호를 자식 프로세스에게 전달하지 못합니다.
Bash 같은 셸은 SIGTERM과 같은 신호를 전달하지 않는데 docker cli, k8s cli는 보통
각 컨테이너의 PID1로 명령을 전달한다는 것에 있습니다.
- 그러나 Bash셸이 그 신호를 무시하기 때문에 docker stop, k8s delete 등의 명령에서
몇 분 이상의 시간이 더 지연될 수도 있습니다. - SIGTERM, SIGINT 같은 신호는 애플리케이션의 안전한 종료를 위해 매우 중요한데
bash가 무시하기 때문에 docker의 경우 어느 정도 기다리다 강제 종료가 이뤄지며
k8s 또한 유예시간을 거친 뒤 모든 프로세스가 비정상적으로 종료될 수 있습니다.
3,4번은 모두 가능하나 단일 애플리케이션을 개발하는 컨테이너에 reap 로직을 넣어야 되는
오버헤드와 경량화를 지향하는 컨테이너의 목적상 적합하지 않습니다.
docker에서 init 시스템을 경량화한 이미지를 추가할 수 있는 옵션을 1.13 버전 이후 추가했으며
이러한 이미지는 종료 신호를 자식에게 전파하는 목적까지 수행하는 경량화 이미지여서
운영 환경에선 가장 안전하고 빠르게 적용할 수 있는 해결책입니다.
현업에선 어떻게 해결했는지
services:
web:
image: myimage:latest
init: true
ports: ["8080:8080"]
위의 옵션 중 init: true라는 설정을 넣어 pid1번이 tini가 대체되며 간단하게 이 문제를 해결할 수 있었습니다.
그 외 docker run, dockerfile에서 간단하게 적용 가능한 예시를 몇 가지 첨부하겠습니다.
docker run --init --name app -p 8080:8080 myimage:latest
---
FROM ubuntu:22.04
RUN apt-get update && apt-get install -y tini
ENTRYPOINT ["/usr/bin/tini", "--", "/app"] # exec-form 권장
부록 1 - kubernetes에서의 해결책
2) docker의 예시처럼 tini 컨테이너를 활용
2번의 예시에 대해선 어느 정도 설명을 드렸던 관계로 PID 네임스페이스 공유에 대해 설명드리겠습니다.
Kubernetes 문서는 Pod에 process namespace sharing을 설정하면 컨테이너 간의 프로세스를
서로 볼 수 있는 공유 PID 네임스페이스가 구성된다고 안내합니다
- 이를 통해 모든 컨테이너가 같은 PID 네임스페이스를 쓰고, 그 네임스페이스의
PID 1(= pause 컨테이너) 가 고아·좀비 프로세스를 wait()로 회수합니다. - 각 애플리케이션 컨테이너가 PID 1의 reaping을 직접 구현하지 않아도 Pod 단위로 일관된 수거가
이뤄지는데 pause컨테이너가 해당 기능을 수행하는 건 네임스페이스 공유가 되어있을때만 입니다.
느낀 점
처음 회사에서 논의했던 문제와 Zombie Process는 사실 밀접한 관계로 엮여있는 이슈는
아니었기 때문에 이게 왜 이슈지? 왜 고쳐야 하지 라는 생각도 사실 잠깐 머릿속에 맴돌았습니다.
하지만 곁가지로 나와있던 이슈라고 해도 누적된다면 PID고갈,운영 혼선을 일으킬 수도 있으며
linux , 컨테이너 환경에서 개념과 연결된 중요한 이슈라고 생각되어 공부하고 해결했던 것 같습니다.
공부를 하며 핵심은 Linux에서 PID1의 역할이 무엇인지였으며 그 역할을 제대로 하지 못할 때
Zombie Process가 생성될 수 있으며 PID 1의 책임을 보장하는 방법을 확인했고 해결했습니다.
거기서 멈추지 않고 컨테이너에서 왜 문제가 발생했고 더 잘 드러났는지 어떤 해결책이 있는지
kubernetes에선 어떻게 해결할 수 있는지도 더 파고들어 공부했던 것 같습니다.
테스트에선 보이지 않던 현상을 실무에서 마주하며, 겸손하게 체계를 갖춰 지속적으로
학습해야 함을 체감했고. init 컨테이너, pause 컨테이너, PID 네임스페이스 등은 별도
글로 정리해보려고 합니다.
이 글을 보며 저뿐만 아니라 다른 분들도 이해해 볼 수 있는 시간이 되었으면 좋겠습니다.
참고한 링크 및 블로그
https://www.ianlewis.org/en/almighty-pause-container?utm_source=chatgpt.com
https://cloud.theodo.com/en/blog/docker-processes-container?utm_source=chatgpt.com
https://kodekloud.com/blog/keep-docker-container-running/?utm_source=chatgpt.com
https://en.wikipedia.org/wiki/Zombie_process?utm_source=chatgpt.com
https://devopsdirective.com/posts/2023/06/container-init-process/?utm_source=chatgpt.com
https://blog.phusion.nl/2015/01/20/docker-and-the-pid-1-zombie-reaping-problem/
https://kubernetes.io/docs/tasks/configure-pod-container/share-process-namespace/
'TroubleShooting > DevOps' 카테고리의 다른 글
| AWS - 동일한 EFS를 여러 PVC로 마운트할 때 발생하는 문제와 해결 (0) | 2025.12.18 |
|---|---|
| Docker - Special DNS 문제 (0) | 2025.08.17 |